
Deep learning is one of the hottest buzzwords in tech and is impacting everything from health care to transportation to manufacturing, and more. Companies are turning to deep learning to solve hard problems, like speech recognition, object recognition, and machine translation.
Everything new breakthrough comes with challenges. The biggest challenge for deep learning is that it requires intensive training of the model and massive amount of matrix multiplications and other operations. A single CPU usually has no more than 12 cores and it will be a bottleneck for deep learning network development. The good thing is that all the matrix computation can be parallelized and that’s where GPU comes into rescue. A single GPU might have thousands of cores and it is a perfect solution to deep learning’s massive matrix operations. GPUs are much faster than CPUs for deep learning because they have orders of magnitude more resources dedicated to floating point operations, running specialized algorithms ensuring that their deep pipelines are always filled.
The good thing is that all the matrix computation can be parallelized and that’s where GPU comes into rescue. A single GPU might have thousands of cores and it is a perfect solution to deep learning’s massive matrix operations. GPUs are much faster than CPUs for deep learning because they have orders of magnitude more resources dedicated to floating point operations, running specialized algorithms ensuring that their deep pipelines are always filled.
GPUs are much faster than CPUs for deep learning because they have orders of magnitude more resources dedicated to floating point operations, running specialized algorithms ensuring that their deep pipelines are always filled.
Now we’re know why GPU is necessary for deep learning. Probably you’re interested in deep learning and can’t wait to do something about it. But you don’t have big GPUs on your computer. The good news is that there are public GPU serves for you to start with. Google, Amazon, OVH all have GPU servers for you to rent and the cost is very reasonable.
In this article, I’ll show you how to set up a deep learning server on Amazon ec2, p2-2xlarge GPU instance in this case. In order to set up amazon instance, here is the prerequisite software you’ll need:
- Python 2.7 (recommend anaconda)
- Cygwin with wget, vim (if on windows)
- Install Amazon AWS Command Line Interface (AWS CLI), for Mac
Here is the fun part:
- Register an Amazon ec2 account at: https://aws.amazon.com/console/
- Go to Support –> Support Center –> Create case (Only for the new ec2 user.)
 Type in the information in the form and ‘submit’ at the end. Wait for up to 24-48 hours for it to be activated. If you are already an ec2 user, you can skip this step.
Type in the information in the form and ‘submit’ at the end. Wait for up to 24-48 hours for it to be activated. If you are already an ec2 user, you can skip this step. - Create new user group. From console, Services –> Security, Identity & Compliance –> IAM –> Users –> Add user
- After created new user, add permission to the user by click the user just created.

- Obtain Access keys: Users –> Access Keys –> Create access key. Save the information.
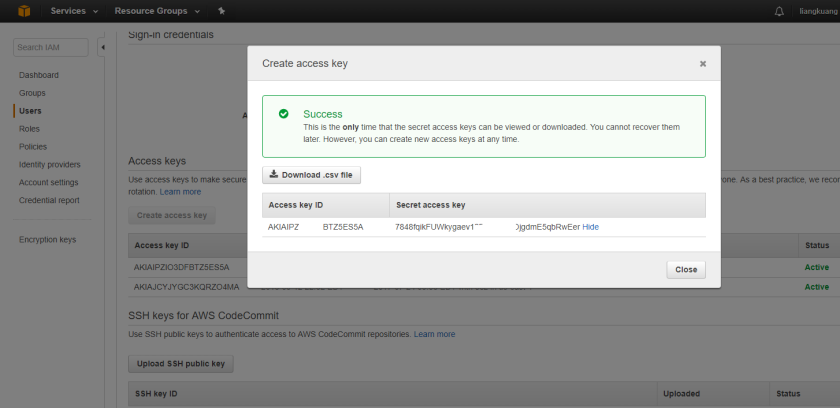
- Now we’re done with Amazon EC2 account, go to Mac Terminal or Cygwin on Windows
- Download set-up files from fast.ai. setup_p2.sh and setup_instance.sh . Change the extension to .sh since WordPress doesn’t support bash file upload
- Save the two shell script to your current working directory
- In the terminal, type: aws configure Type in the access key ID and Secret access key saved in step 5.
- bash setup_p2.sh
- Save the generated text (on terminal) for connecting to the server
- Connect to your instance: ssh -i /Users/lxxxx/.ssh/aws-key-fast-ai.pem ubuntu@ec2-34-231-172-2xx.compute-1.amazonaws.com
- Check your instance by typing: nvidia-smi
- Open Chrome Browser with URL: ec2-34-231-172-2xx.compute-1.amazonaws.com:8888Password: dl_course
- Now you can start to write your deep learning code in the Python Notebook.
- Shut down your instance in the console or you’ll pay a lot of money.
For a complete tutorial video, please check Jeremy Howard’s video here.
Tips:
The settings, passwords are all saved at ~/username/.aws , ~/username/.ipython.


